NCBIのBLAST機能を全部概説してみる


分子生物学の分野の研究をしている人はとってもお世話になっているだろうNCBIのBLAST機能。
もうこのBLASTなしには僕たちの研究は進まないと思います。
特に、BLASTの下にあるSpecialized BLASTは場合によってはとっても便利なサービスになります。

とっても便利なサービスなのですが、僕の周りの学生を見ましてもこのBLASTを使いこなしている人はとっても少ないですね。
そこで今日は、このSpecialized BLASTを一個一個簡単に紹介していきたいと思います。
日本初!
目次です。
- SmartBLAST
- Primer-BLAST
- MOLE-BLAST
- Find conserved domains in your sequence
- Find sequences with similar conserved domain architecture (cdart)
- Search sequences that have gene expression profiles (GEO)
- Search immunoglobulins and T cell receptor sequences (IgBLAST)
- Screen sequence for vector contamination (vecscreen)
- Align two (or more) sequences using BLAST (bl2seq)
- Search protein or nucleotide targets in PubChem BioAssay
- Search SRA by experiment
- Constraint Based Protein Multiple Alignment Tool
- Needleman-Wunsch Global Sequence Alignment Tool
SmartBLAST
つい最近出てきたサービスです。
SmartBLASTはタンパクの配列(FASTA形式)をクエリーとして、タンパクのデータベースを対象として相同的なタンパクを見つけてくれるサービスです。
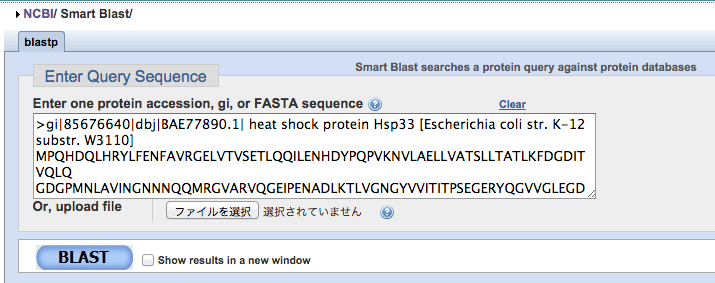
タンパクの配列をFASTA形式で入力する(今回の配列は大腸菌のheat shock protein)
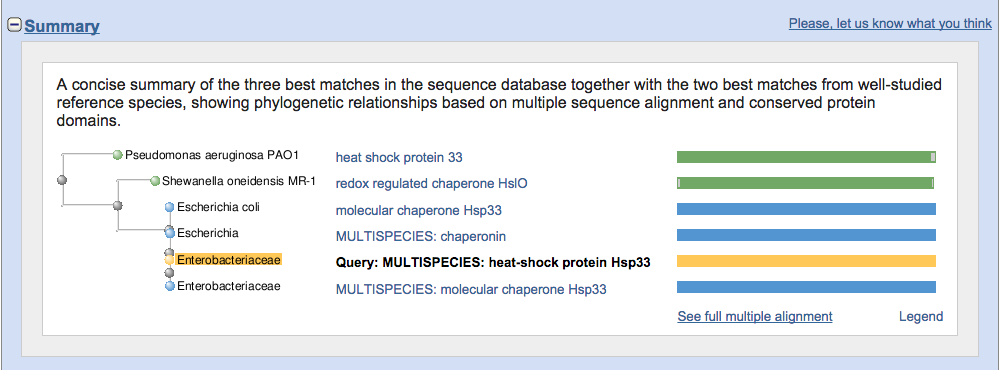
クエリーに相同性のあるタンパク一覧がデータベースから選ばれる。サマリーでは、系統的に近い生物でのホモログも教えてくる。
Primer-BLAST
Primer-BLASTは、指定した塩基配列内で自動的にプライマーをデザインしてくれるサービスです。
Primer-BLASTを使うか使わないかであなたの研究は180度変わります。
詳しくはPrimer-BLASTの使い方で解説しています。
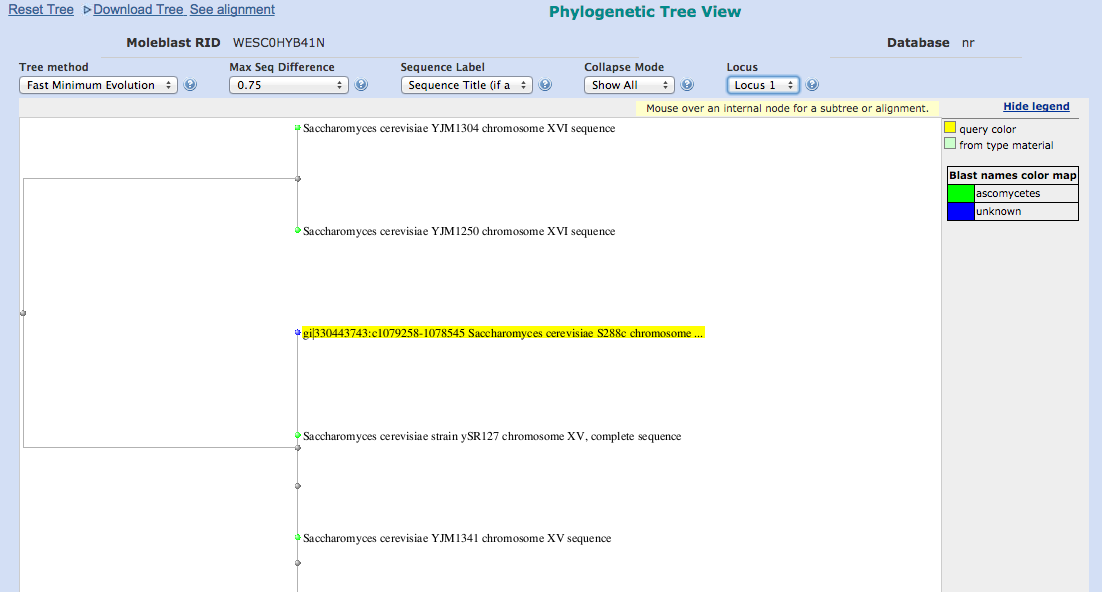
MOLE-BLAST
こちらも最近出てきたサービスです。
FASTA形式で塩基配列を送ると、その遺伝子を系統的に分類してくれるサービスです。
分類学者なんかにうってつけのサービスですね。
Find conserved domains in your sequence
クエリーで入力した配列内にあるconserved domainを探してくれるサービスです。
このドメインサーチから遺伝子機能を予測することも多いので便利ですね。
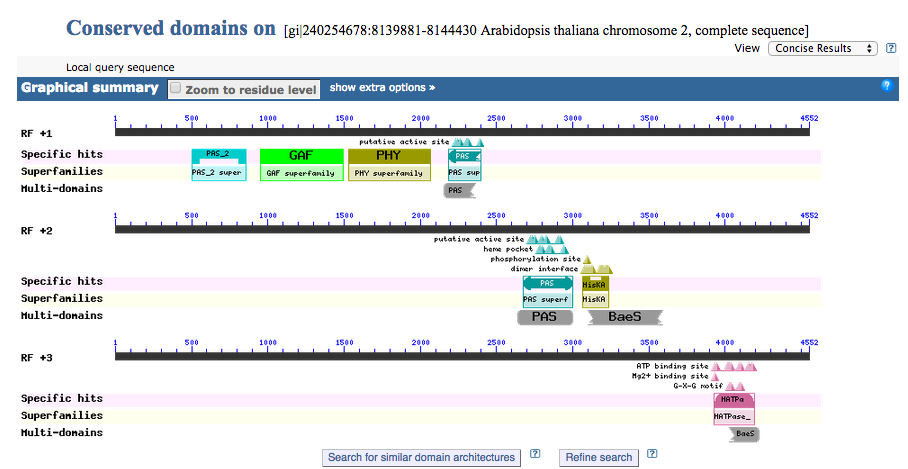
クエリーはナズナのphyB。phyBに特徴的なドメインが保存されているのがわかる。
Find sequences with similar conserved domain architecture (cdart)
こちらはタンパク配列をクエリーとして、conserved domainを探してくれるサービス。
上とそこまで変わらない気がします。

クエリーはAspergillus nigerのphyBタンパク
Search sequences that have gene expression profiles (GEO)
こちらは、入力した配列に相同性がありかつgene expression profile (GEO)がある遺伝子をピックアップしてくれるサービスです。

Search immunoglobulins and T cell receptor sequences (IgBLAST)
イミュノグロブリンとT細胞のシーケンスをblastできるサービスです。
詳しくは
http://nar.oxfordjournals.org/content/41/W1/W34.long
で解説されていますのでご一読下さい。
(僕は免疫分野が苦手)
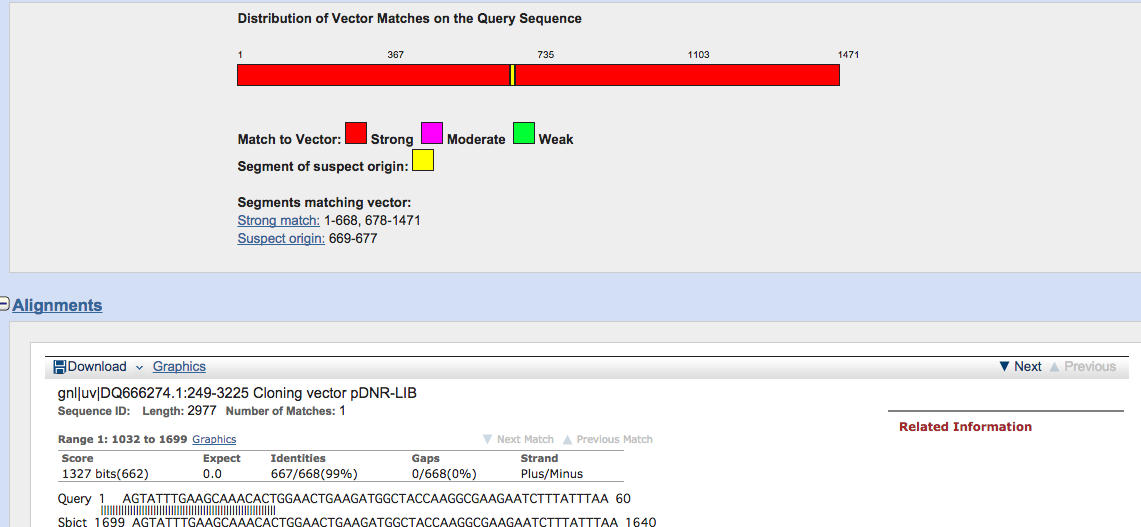
Screen sequence for vector contamination (vecscreen)
こちらは、クエリー配列にベクターやリンカー、アダプターの配列があるかを調べてくれるサービス。
クローニング後などの確認に威力を発揮します。
Align two (or more) sequences using BLAST (bl2seq)
入力した2つ以上の配列をアラインメントして、相同性を調べてくれるサービスです。
例えばとある遺伝子Aのオーソログが他の生き物であったとして、どれくらい似ているのかを調べるときに便利です、
僕はよく使いますね。

Search protein or nucleotide targets in PubChem BioAssay
タンパクか塩基配列を入力すると、PubChem BioAssayのデータベースに当ててくれるサービス。
正直僕はあまり使いませんね
Search SRA by experiment
クエリーの配列をSRAデータベースに当ててくれるサービス。
SRAとは、Sequence Read Archive)の略で、超高速次世代シーケンサーが出力したデータを貯蓄しているデータベース。欧州の EBI と日本の DDBJ が同期を行っている。
詳しくはこちらで解説されているので参考までに。
Constraint Based Protein Multiple Alignment Tool
2つ以上のタンパク配列を入力することで、アラインメントをしてくれるサービス。

Needleman-Wunsch Global Sequence Alignment Tool
Needleman-Wunsch法でグローバルアラインメントしてくれるサービス。
詳しくはこちらで解説されているのでご参考に。
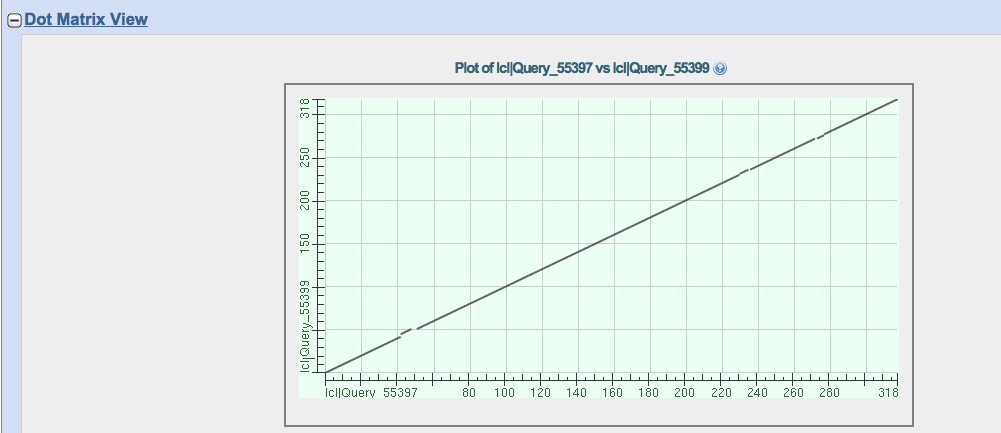
グローバルアラインメントの結果
関連記事




